Especificar imagen base
FROM node:16-alpine

Primeramente indicar, como ya hemos dicho en una publicación previa, que esta aplicación tiene como objetivo el aprendizaje. En una aplicación normal no se seguirá la estructuración de la aplicación que hemos seguido aqui.
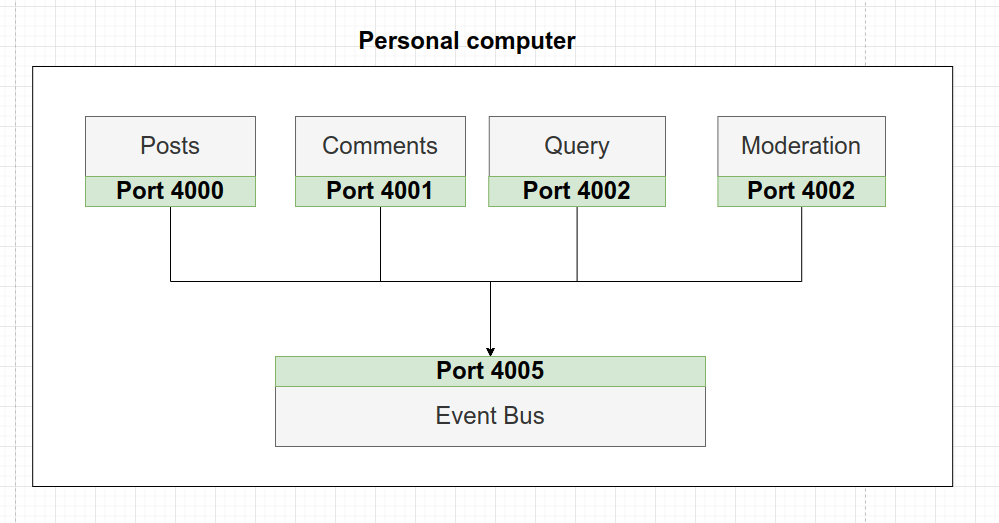
En la aplicación indicada en esa publicación, para identificar los diferentes servicios indicamos como url localhost y el número de puerto donde corre el servicio, eso funciona correctamente. Pero ahora, lo que queremos es desplegar la aplicación on-line. Para ello debemos alquilar una máquina virtual en alguna de las opciones existentes: Digital Ocean, AWS, Microsoft Azure, Google Cloud, etc…
Pensemos en un nuevo escenario al desplegar la aplicación on-line. Nuestro blog empieza a recibir miles de visitas y los usuarios sobrecargan Comments Service creando comentarios. En consecuencia, para dar respuesta a toda esta alta demanda nos vemos obligados a crear nuevas instancias del servicio.
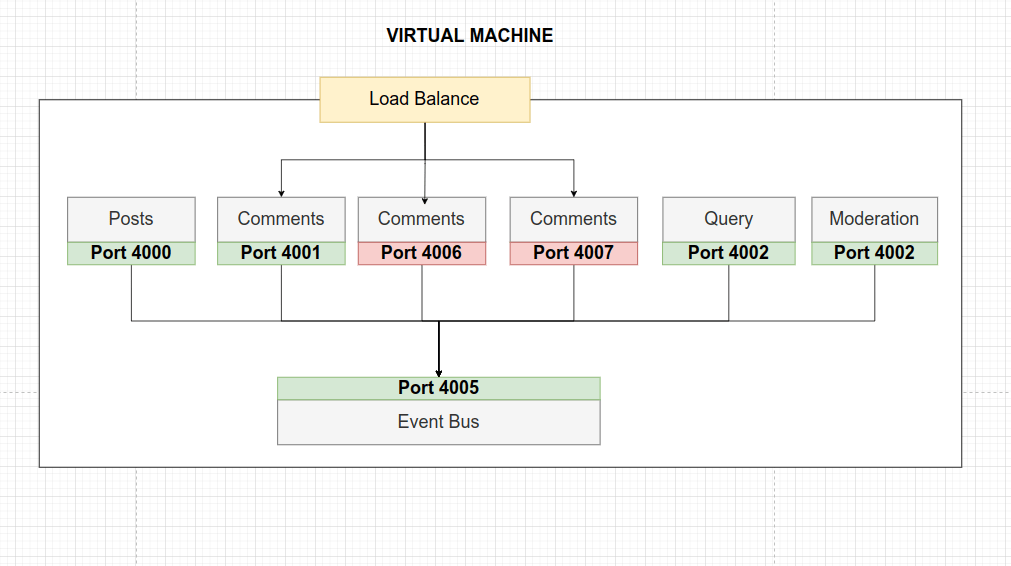
Seguidamente, a estas nuevas instancias debemos asignarles un nuevo puerto de escucha para establecer comunicación con Event Bus y debemos implementar el código necesario en Event Bus para comunicarnos con estos nuevos puertos de servicios. Como resultado, vamos a crear un fuerte acoplamiento entre los componentes. Debido a ello, cada vez que queramos agregar nuevas instancias de servicios debemos detener la aplicación, modificar el código y desplegar nuevamente.
Al mismo tiempo, al crear nuevas instancias de servicios, sobrecargamos la máquina virtual. Como solución, podríamos alquilar otra máquina virtual para implementar las nuevas instancias y evitar esta sobrecarga.Pero nuevamente, debemos indicarle a Event Bus cómo llegar a la dirección IP de esta nueva máquina y a los servicios correspondientes. Un trabajo realmente tedioso.
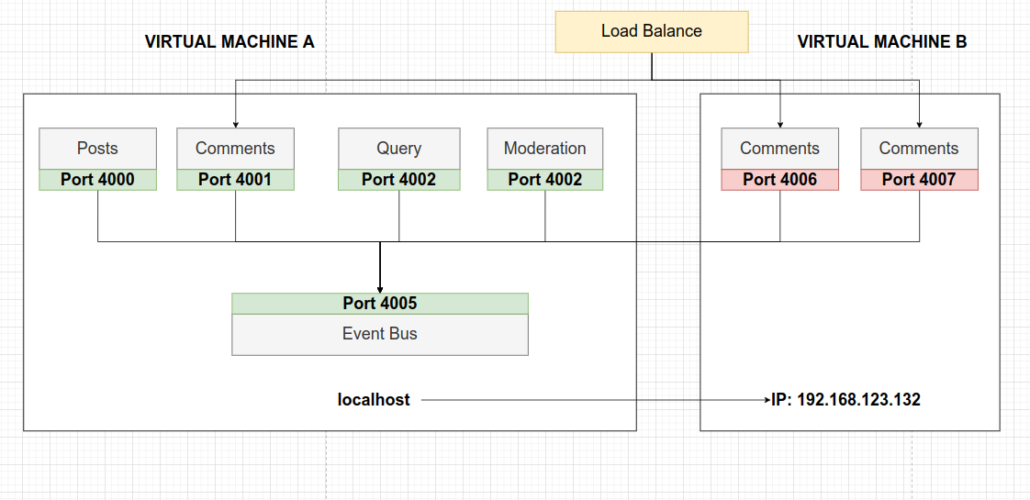
Además, si queremos administrar estas nuevas instancias bajo demanda (encenderlas o apagarlas durante ciertas horas del día), debemos implementar una condición en el código para que Event Bus sepa cuándo puede comunicarse con ellas. Todo esto es demasiado complejo, demasiado confuso, y probablemente no haya forma de que podamos lograrlo tan fácilmente. En conclusión, esta no es la solución ideal.
Con Docker vamos a crear contenedores. Un contenedor es como un entorno computacional aislado que contiene todo lo necesario para ejecutar un solo programa. Entonces, si nuestros servicios deben de funcionar de la forma más independiente posible, esto favorecerá este comportamiento.
Por un lado, los contenedores disponen de todo lo que necesita un programa para iniciarse y funcionar.
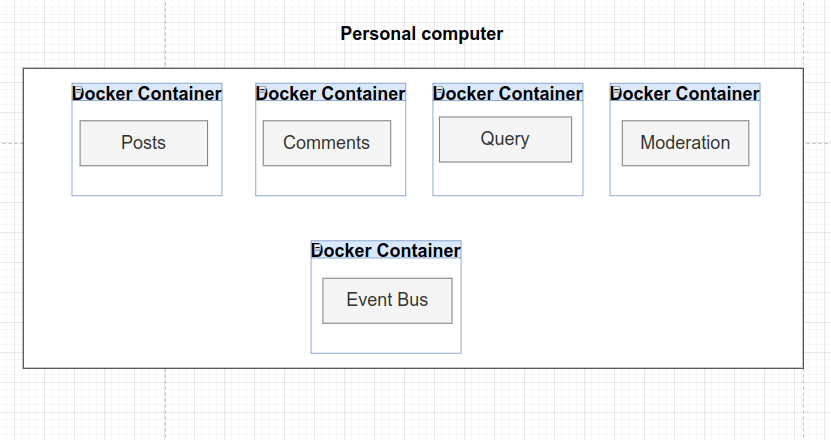
Por otro lado, en caso de necesitar más instancias de un servicio en particular, Docker nos permite crear nuevos contenedores de un mismo servicio.
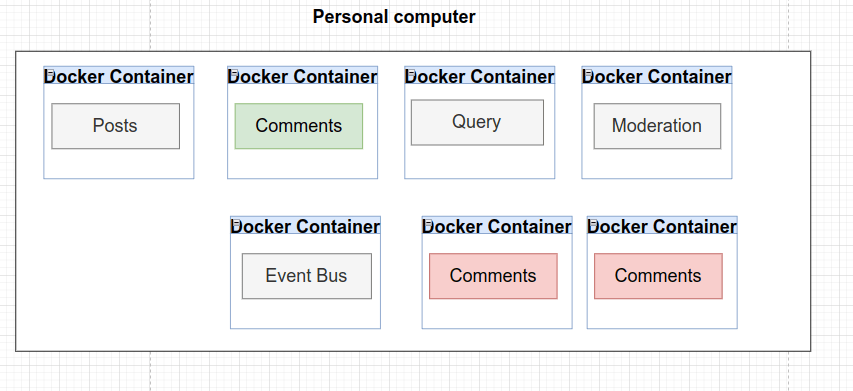
La facilidad que tiene Docker para poner un marcha un programa es algo que le permite funcionar muy bien con Kubernetes. Para seguir este camino, hemos dockerizado todos los servicios creando un Dockerfile en cada servicio.
Además, para excluir del proceso de compilación todas las dependencias existentes en la carpeta node_modules, hemos creado el archivo .dockerignore en todos los servicios.
Respecto de la orquestación de Servicios con Kubernetes. Como introducción indicar que Kubernetes, también conocido como K8s, es una herramienta para poner en marcha un montón de contenedores diferentes. Primeramente le daremos una configuración para describir cómo queremos que nuestros contenedores se ejecuten e interactúen entre sí. Después, el se encargará de establecer la comunicación entre los servicios y, si es necesario, escalar la aplicación creando nuevos contenedores según la demanda.
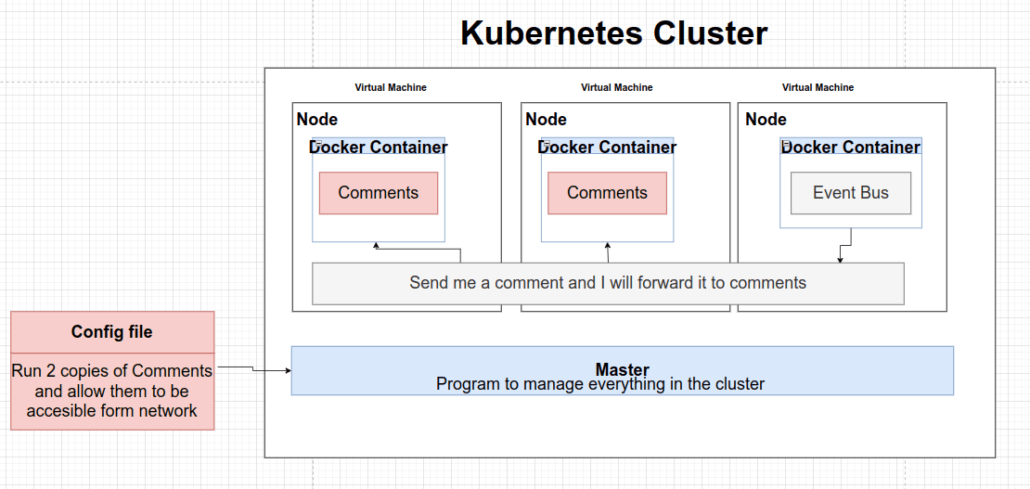
Como decíamos, con los archivos de configuración le indicaremos a K8s cuales son los diferentes Deployments, Pods y Services que queremos crear. Generalmente, es una buena practica que guardaremos estos archivos en nuestro código fuente porque nos servirán como documentación. Por otra parte, es posible crear estos objetos mencionados sin los archivos de configuración, pero no es una práctica recomendada.
Para poder probar estos comandos hemos creado un archivo de configuración que define un Pod: post.old
Para procesar el archivo de configuración, debemos cambiar la actual extensión del archivo por la extensión de archivo ‘yaml’.
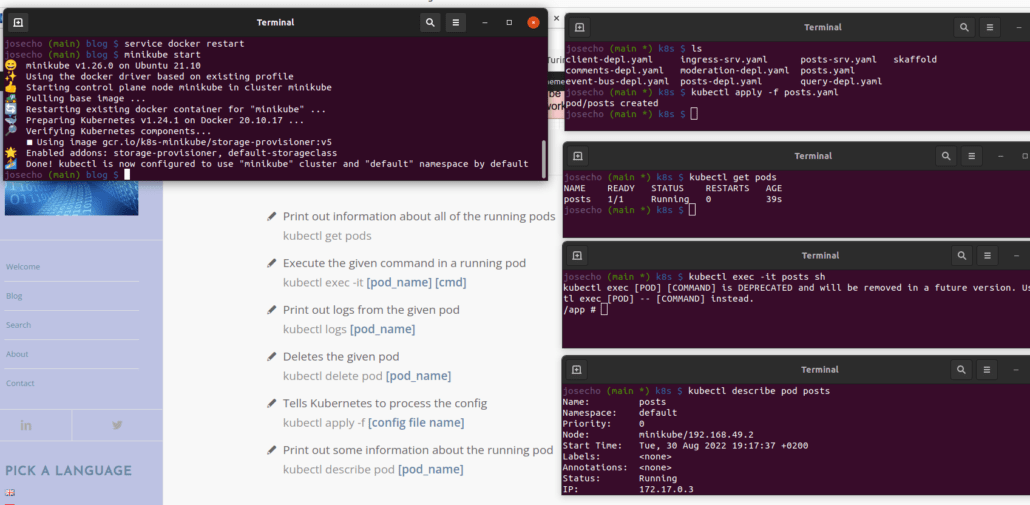
Finalmente, debemos eliminar el Pod y cambiar la extensión del archivo de configuración nuevamente (post.old), normalmete no se suelen crear pods con este estilo de archivo de configuración.
kubectl delete pod posts
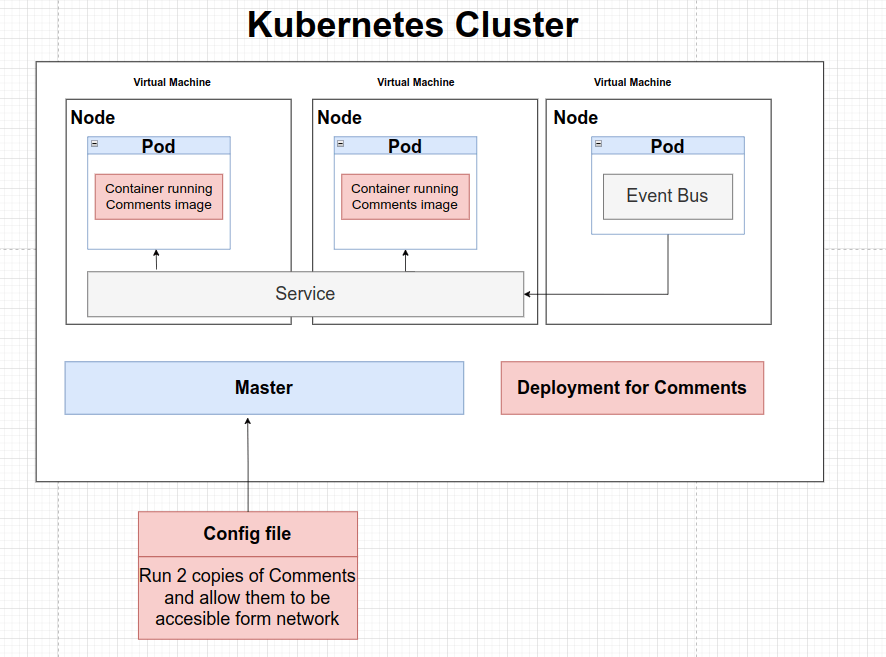
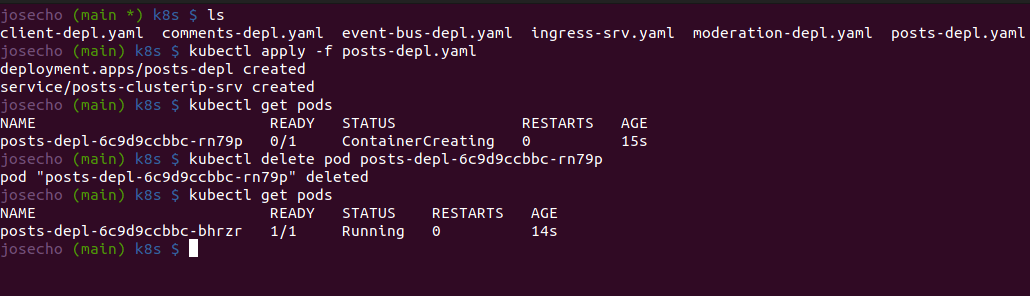
Sin embargo, en lugar de crear estos Pods directamente, normalmente vamos a crear algo llamado Deployment: post-depl.yaml
Este tipo de objeto se encargará de crear los Pods, actualizar sus versiones, etc…
Si creamos un Deployment y eliminamos el Pod que ha creado, entonces se encarga de recrearlo por nosotros. Para eliminar los Pods asociados al Deployment debemos eliminarlo.
cd /posts
Haz un cambio en el archivo index.js
console.log('v2');
cd /posts docker build -t josecho/posts:0.0.5 .
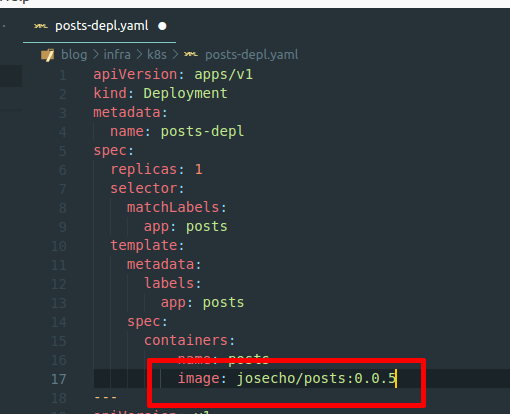
kubectl apply -f posts-depl.yaml
cd /infra/k8s
No es necesario especificar :latest, se puede indicar de esta forma image: josecho/posts
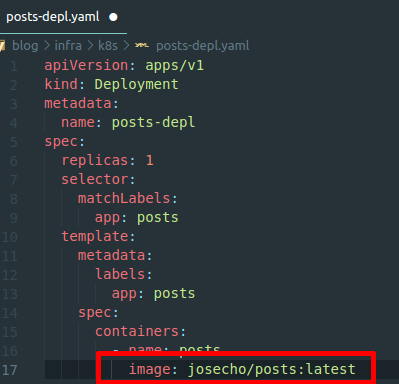
kubectl apply -f posts-depl.yaml
cd /posts
Haz un cambio en el archivo index.js
console.log('v3');
docker build -t josecho/posts .
docker push josecho/posts
kubectl rollout restart deployment posts-depl
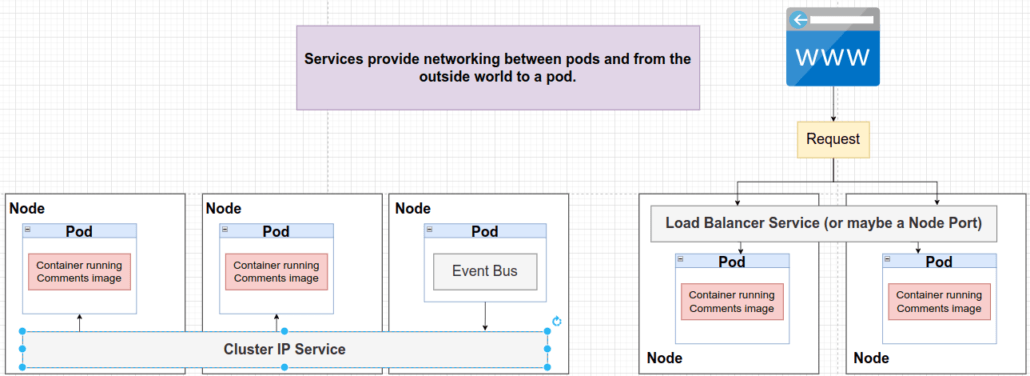
Generalmente, en el día a día solo utilizaremos los servicios de Cluster IP y Load Balancer.
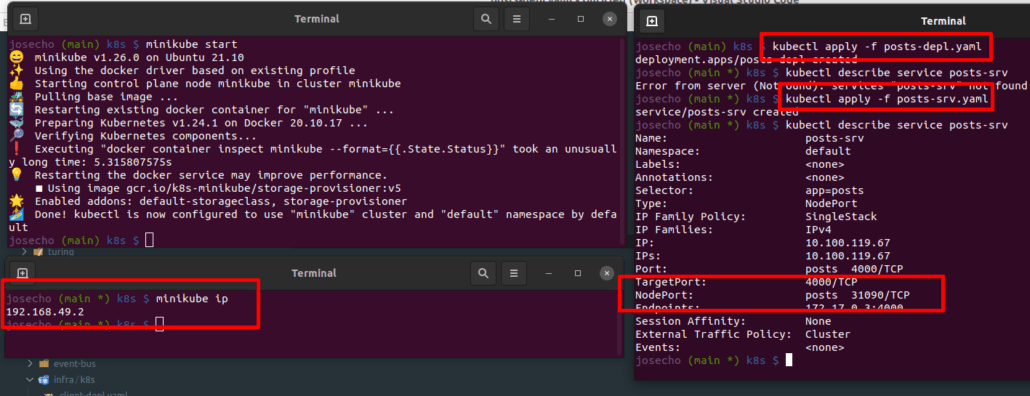
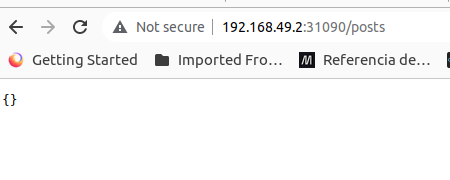
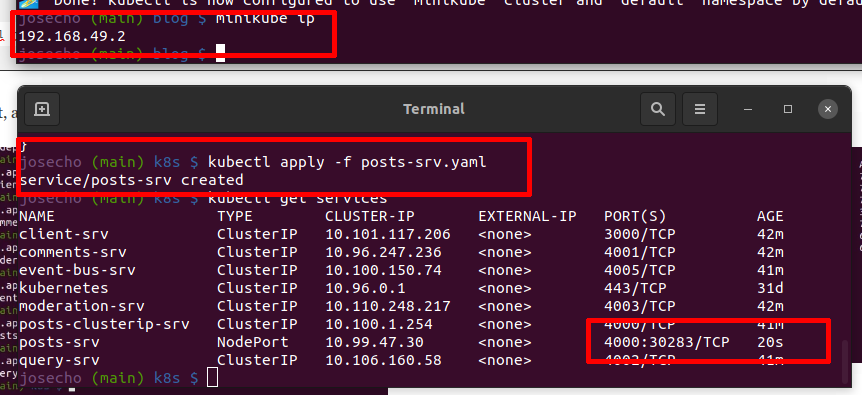
En el caso de que usemos GNU/Linux como sistema operativo entonces Docker usará Minikube. Por tanto, en nuestro ordenador personal debemos acceder a través de la IP que utiliza Minikube. Para otros sistemas operativos la dirección IP será localhost: localhost:31090/posts.
En la imagen que mostramos a continuación podemos ver como se crea el servicio de tipo NodePort a través de su archivo de configuración.
A continuación, accedemos al mismo a través del navegador.
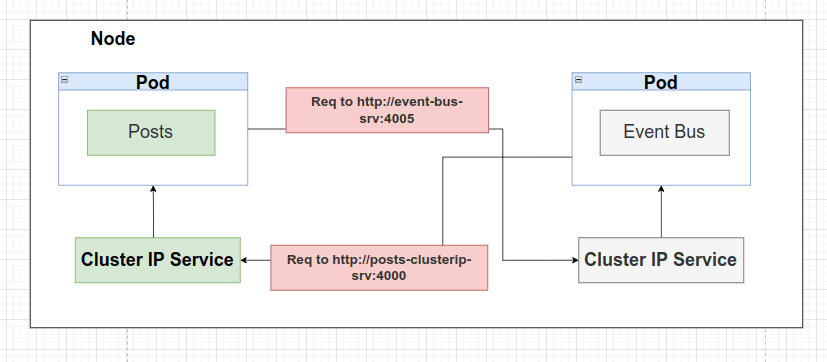
En lugar de comunicarnos con un pod a través de la URL compuesta por localhost y el número de puerto del servicio (http://localhost:4005), configuraremos una URL fácil de recordar.
cd event-bus docker build -t josecho/event-bus . cd posts docker build -t josecho/posts .
cd event-bus docker push josecho/event-bus . cd posts docker push josecho/posts
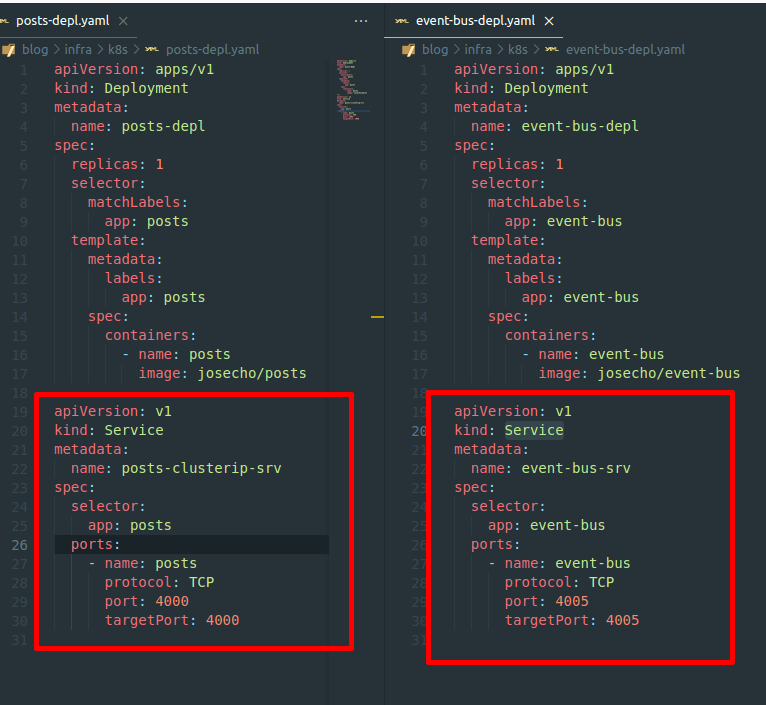
cd /infra/k8s kubectl apply -f post-depl.yaml kubectl apply -f event-bus-depl.yaml kubectl get pods kubectl get services
No usaremos más localhost como parte de la URL.
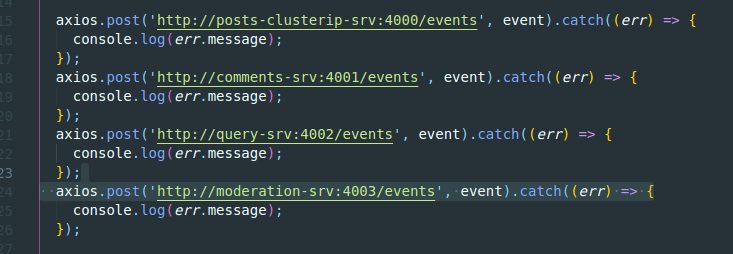
Por supuesto, seguiremos los mismos pasos con todos los servicios de la aplicación.
kubectl apply -f [deployment name]
En este punto, todos los pods se crearán con sus IP Cluster Services asociados.
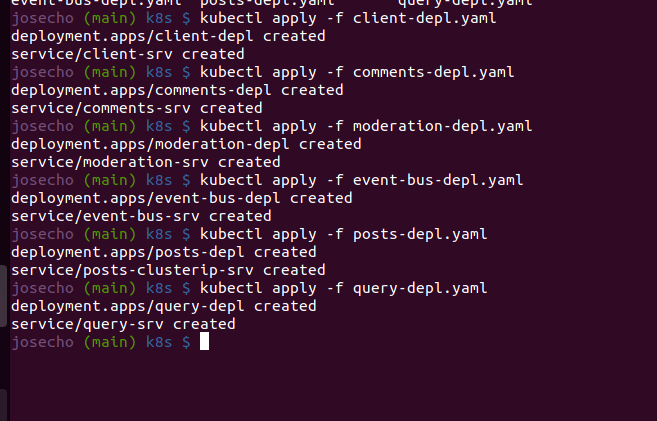
No debemos olvidarnos de subir las imágenes a Docker Hub y actualizar los Deployments cuando sea necesario.
docker push [ìmage name] kubectl rollout restart deployment [deployment name]
Como mencionamos anteriormente, NodePort Service se usa con fines de desarrollo. Veámoslo.
kubectl apply -f post-srv.yaml
En un primer lugar, con la herramienta Postman tal y como mostramos en la siguiente imagen creamos una publicación.
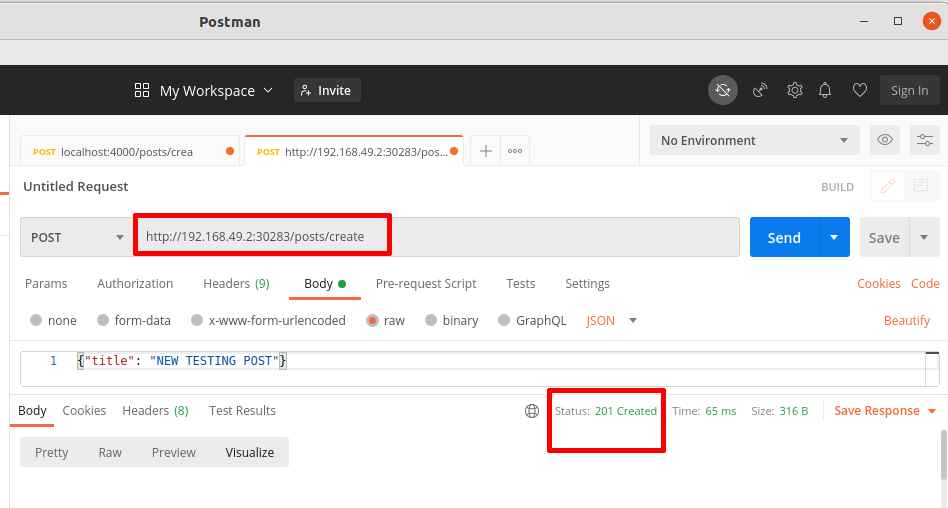
Después de eso, Comment Services debe recibir un evento sobre la creación de una publicación. Por tanto, lo verificamos en el registro del pod.
kubectl logs [pod name]
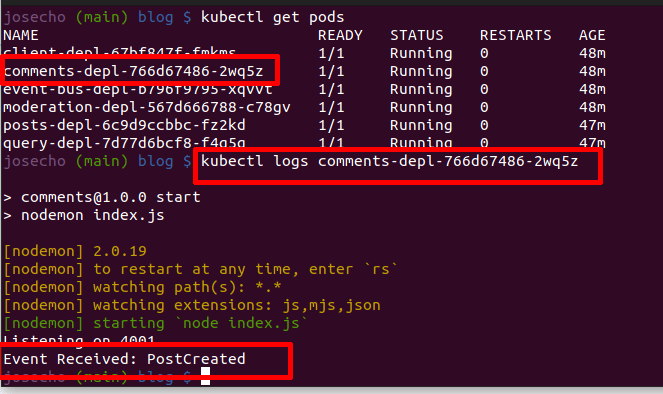
Finalmente, como el servicio ha recibido el evento concluimos que la comunicación está funcionando correctamente.
Cuando un usuario abre su navegador y navega a nuestra aplicación por primera vez, su navegador se conectará al servidor de desarrollo de la aplicación React. El objetivo de este servidor de desarrollo es generar archivos HTML, JavaScript y CSS a partir del código que hemos escrito en nuestra aplicación React. Por tanto, en respuesta al navegador del usuario se le entregan estos archivos y la aplicación React se inicia dentro del navegador.
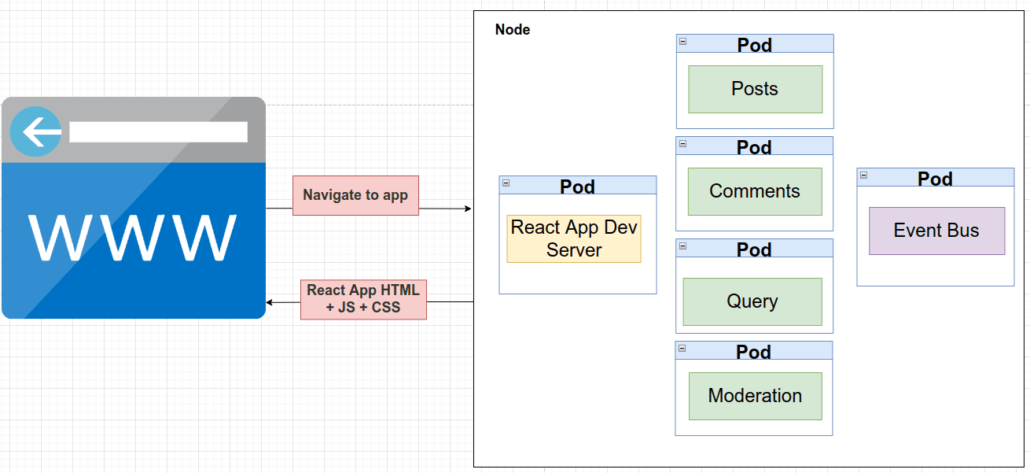
En cualquier caso, lo que el servidor de desarrollo de la aplicación React no hace, es crear ninguna petición hacia los otros servicios en ningún momento.
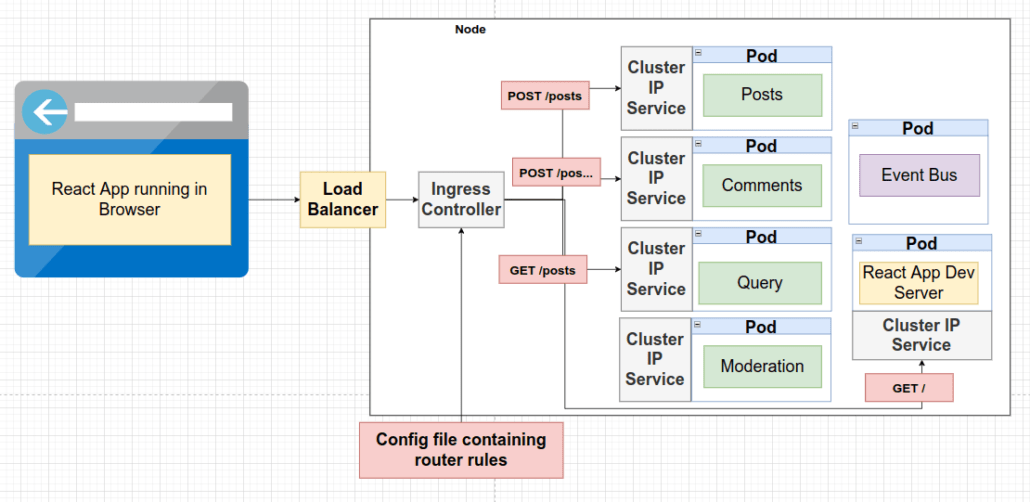
Así que, otros componentes serán los responsables de manejar el tráfico de las peticiones. A efectos del diagrama mostrado encima, solo diremos que vamos a enviar tráfico al pod.
Sobre la relación existente entre el Load Balancer y el Ingress Controller, de una manera muy simplista para que sea fácil de entender digamos que:
Se trata simplemente de llevar tráfico a nuestro clúster. Le diremos a Kubernetes que se comunique con su proveedor y disponibilice un balanceador de carga para que lleve el tráfico a un solo pod.
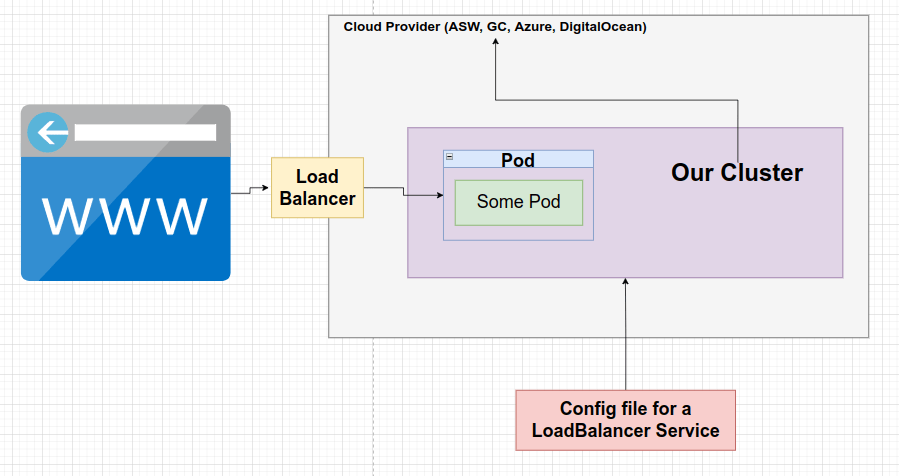
Load Balancer Service le indicará a nuestro clúster que se comunique con su proveedor de la nube. Que se comuníquese directamente con AWS, Google Cloud o Azure y disponibilice un balanceador de carga. Este va a existir completamente fuera de nuestro clúster y es parte de Google Cloud, AWS o Azure.
Hablamos sobre reglas de enrutamiento o de tener alguna configuración de enrutamiento que envíe solicitudes al pod apropiado. Es decir, un pod con un conjunto de reglas de enrutamiento para distribuir el tráfico a otros servicios. Técnicamente, Ingress e Ingress Controller son dos cosas diferentes, pero nos referiremos a ellos como términos intercambiables.
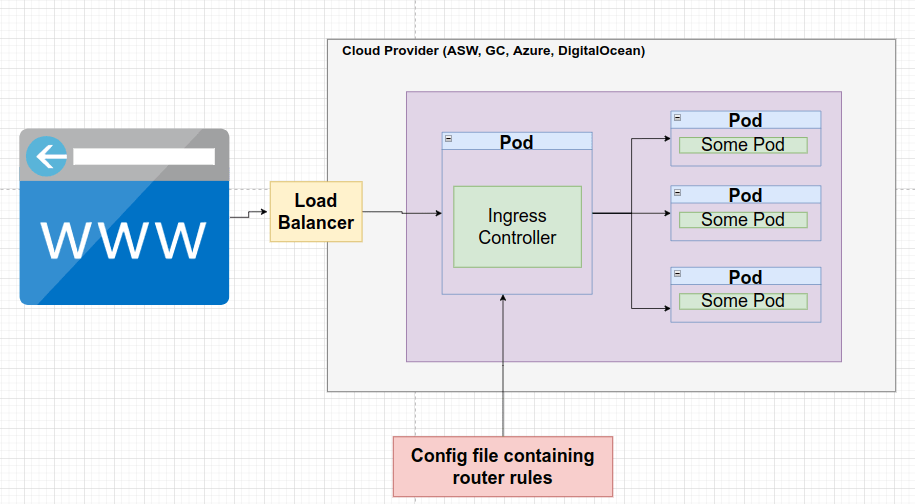
Estamos usando Ingress-nginx. Hay otro proyecto que hace lo mismo y que tiene nombre casi idéntico Kubernetes-ingress. Comprueba que está instalando Ingress Nginx y no Nginx Ingress, que es una biblioteca totalmente diferente e incompatible. Guía de instalación.
Nuestro sistema operativo es GNU/LINUX, debemos ejecutar el siguiente comando en el proceso de instalación:
minikube addons enable ingress #run to make sure the ingress-nginx-controller is in running STATUS. kubectl -n kube-system get pods
En el archivo de configuración indicamos como host el dominio posts.com.
spec:
rules:
-host:posts.com
Para que este dominio sea reconocido, en nuestro ordenador personal debemos editar el archivo /etc/hosts indicando la dirección IP a la que estará asociado el dominio, en este caso la IP de minikube.
[minikube IP] posts.com
Entonces, si cargamos el archivo de configuración de Ingress-nginx
kubectl apply -f ingress-srv.yaml
En el navegador, la url del dominio indicado debe de responder correctamente.
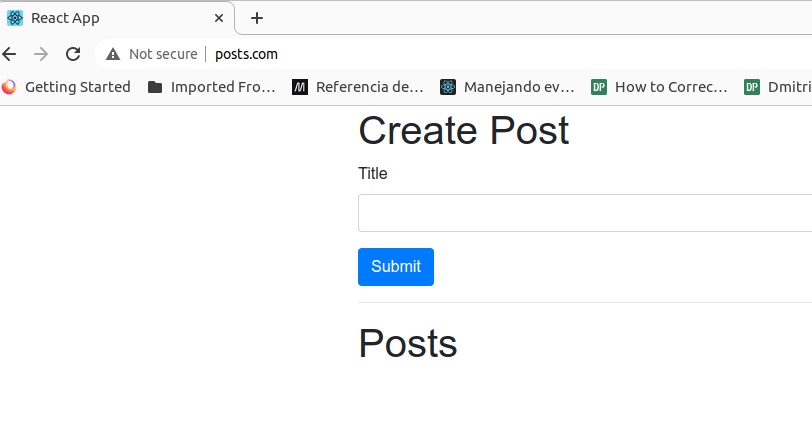
Nuestra aplicación funciona bien dentro del clúster, lo cual es genial. Todo se ejecuta en nuestro ordenador personal, en nuestro entorno de desarrollo. Pero hacer cambios en nuestro código base es un verdadero fastidio, un proceso de desarrollo desagradable. Entonces, cuando estemos desarrollando código activamente dentro de un clúster, en vez de seguir todo este proceso de desarrollo usaremos una herramienta llamada Skaffold.
Skaffold es una herramienta de línea de comandos que usaremos para realizar automáticamente muchas tareas diferentes en nuestro entorno de desarrollo de kubernetes. Específicamente, podemos usar Scaffold en un entorno de producción, pero sólo nos enfocaremos en usarlo en el desarrollo. Lo que más nos interesa de Skaffold es que hace que sea muy fácil actualizar el código en un pod en ejecución.
Este archivo de configuración le dirá a SKaffold cómo administrar todos los diferentes subproyectos dentro de nuestro clúster.
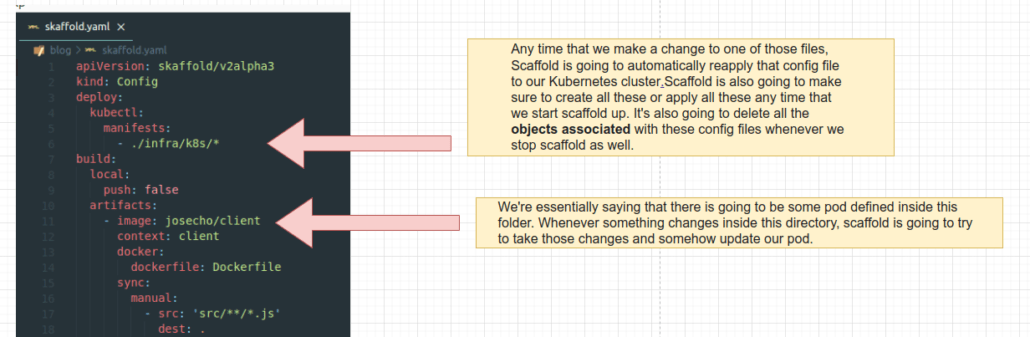
Para poner en marcha skaffold ejecutaremos el comando:
skaffold dev
Increíble, todo funcionando.
Cualquier cambio que realicemos se verá reflejado automáticamente, en nuestro caso se realizan actualizaciones a dos niveles. Por un lado tenemos trabajando a Nodemon y por otro a Skaffold. Hasta ahora hemos puesto a funcionar nuestra aplicación en el clúster que tenemos instalado en nuestro ordenador personal pero no hemos publicado la aplicación online en ningún proveedor de la nube. En la próxima publicación seguiremos avanzando en este tema.
 Google Cloud: Entorno de desarrollo
Google Cloud: Entorno de desarrollo
Dejar un comentario
¿Quieres unirte a la conversación?Siéntete libre de contribuir!