
Machine Learning
“We shall not go any further into the nature of this oracle apart from saying that it cannot be a machine,” Turing explained (or did not explain). “With the help of the oracle we could form a new kind of machine (call them O-machines).” Turing showed that undecidable statements, resistant to the assistance of an external oracle, could still be constructed, and the Entscheidungsproblem would remain unsolved. The Universal Turing Machine of 1939 gets all the attention, but Turing’s O-machines of 1939 may be closer to the way intelligence (real and artificial) works: logical sequences are followed for a certain number of steps, with intuition bridging the intervening gaps.
Turing’s Cathedral. George Dyson.
Following the series of courses published by Stephen Grider on the Udemy platform, I have started one course called ‘Machine Learning with Javascript: Master Machine Learning from scratch using Javascript and TensorflowJS with hands-on projects‘.
TensorflowJS is licensed under Apache License 2.0. Compatible with versión 3 of GPL.
Stephen tells us about conversations he has had with people who have been working in the world of machine learning for some time. From what they say, learning about ML would be something that would be available to people without the need for deep knowledge about algorithms.
The key would be in the knowledge of a series of fundamental operations:

The people who learn machine learning the fastest and the people who have success in industry and real life projects applying this stuff are not really the people who understand the absolute inner workings of every last one these algorithms. The people who really pick up the stuff quickly are the people who can experiment with these algorithms very quickly because they have an exceptionally strong basis in these fundamental operations
Stephen Grider
Let’s try to identify some of these fundamental concepts and operations
Imagine you are an analyst at a small city with a big flooding problem.
City Manager asks you…
If it rains 240mm this year, how much flood damage will there be?
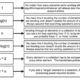
Problem Solving Process
Identify data that is relevant to the problem
‘Features’ are categories of data points that affect the value of a ‘label’.

Assemble a set of data related to the problem you’re trying to solve.
Datasets almost always cleanup or formating.
.

Decide on the type of output you are predicting
There are more, but we focus on two of them.
Regression used with continous values, classification used with discrete values.
.

Based on type of output, pick an algorithm that will determine a correlation between your ‘features‘ and ‘labels‘ and use model generated by algorithm to make a prediction
Many different algorithms exist, each with pros and cons.
Models relate the value of ‘features‘ to the value of ‘labels‘.
.

Our Prediction Was Bad!
But, doing this is pointless if we don’t have a good way to compare accuracy with differents settings!
Finding an Ideal K
- Record a bunch of data points
- Split that data into a ‘training’ set and a ‘test’ set
Training = {[22,33,45,66], [23,76,45,54],[47,98,23,12],[54,3,90,22]} <---shuffle.
Test = {[12,33,44,44], [55,65,87,99],[47,98,23,12],[54,3,90,22]} <---shuffle.
- For each ‘test’ record, run KNN using the ‘training’ data
Does the result of KNN equal the ‘test’ record bucket?
Based on this small introduction, we can identify some of these fundamental points
The standardization of the ‘Features’ is something that we have not seen in this little introduction, but it is something that is not of interest for what I want to reflect in this post.
On the other hand, if we have seen concepts such as:
- Record a bunch of data points
- Labels
- Features
- Split data: ‘training data set’ and ‘test data set’ (randomly disordered).
The record of large amount of data that we are going to use, we are going to provide to the algorithm model that makes the predictions from the hard disk of our computer. This data will be stored in a CVS file.
There are several libraries that allow us to carry out this data load, but I will present a code that will allow us to do the same and at the same time allow customization according to our needs.



Leave a Reply
Want to join the discussion?Feel free to contribute!